Building Agentic AI Foundation Solutions on AWS
View AWS reference architectureDecision this supports
Should we adopt AWS's agentic AI foundation reference for a startup-scale RAG product?
THE SOURCE
Source write-up
Purpose
AWS reference architecture (reviewed January 29, 2026) for an authenticated customer-support agent: Cognito at the edge, Amazon Bedrock AgentCore (Runtime, Identity, Memory, Gateway, Observability) wrapping a LangGraph agent, LiteLLM as a multi-provider model gateway, and a Bedrock Knowledge-Base RAG path over OpenSearch + S3, with Langfuse and CloudWatch for telemetry. Independent evaluation for startup fit.
Components
- Amazon Bedrock AgentCore Runtime
- Amazon Bedrock AgentCore Identity
- Amazon Bedrock AgentCore Memory
- Amazon Bedrock AgentCore Gateway
- Amazon Bedrock AgentCore Observability
- Amazon Bedrock Models
- Amazon Bedrock Guardrails
- Amazon Bedrock Knowledge Base
- Amazon OpenSearch Vector DB
- Amazon S3
- Amazon Cognito
- Amazon CloudWatch
- LangGraph
- LiteLLM
- Langfuse
- Zendesk
Vendor's stated assumptions
- Single-agent LangGraph topology with a managed AgentCore runtime layered around it.
- AWS-native control plane (Cognito, CloudWatch, Bedrock Knowledge Base, OpenSearch) with LiteLLM preserving multi-provider model optionality.
- Guardrails sit in front of the model layer; safety is part of the data path, not bolted on.
Show full source write-up
What this artefact evaluates
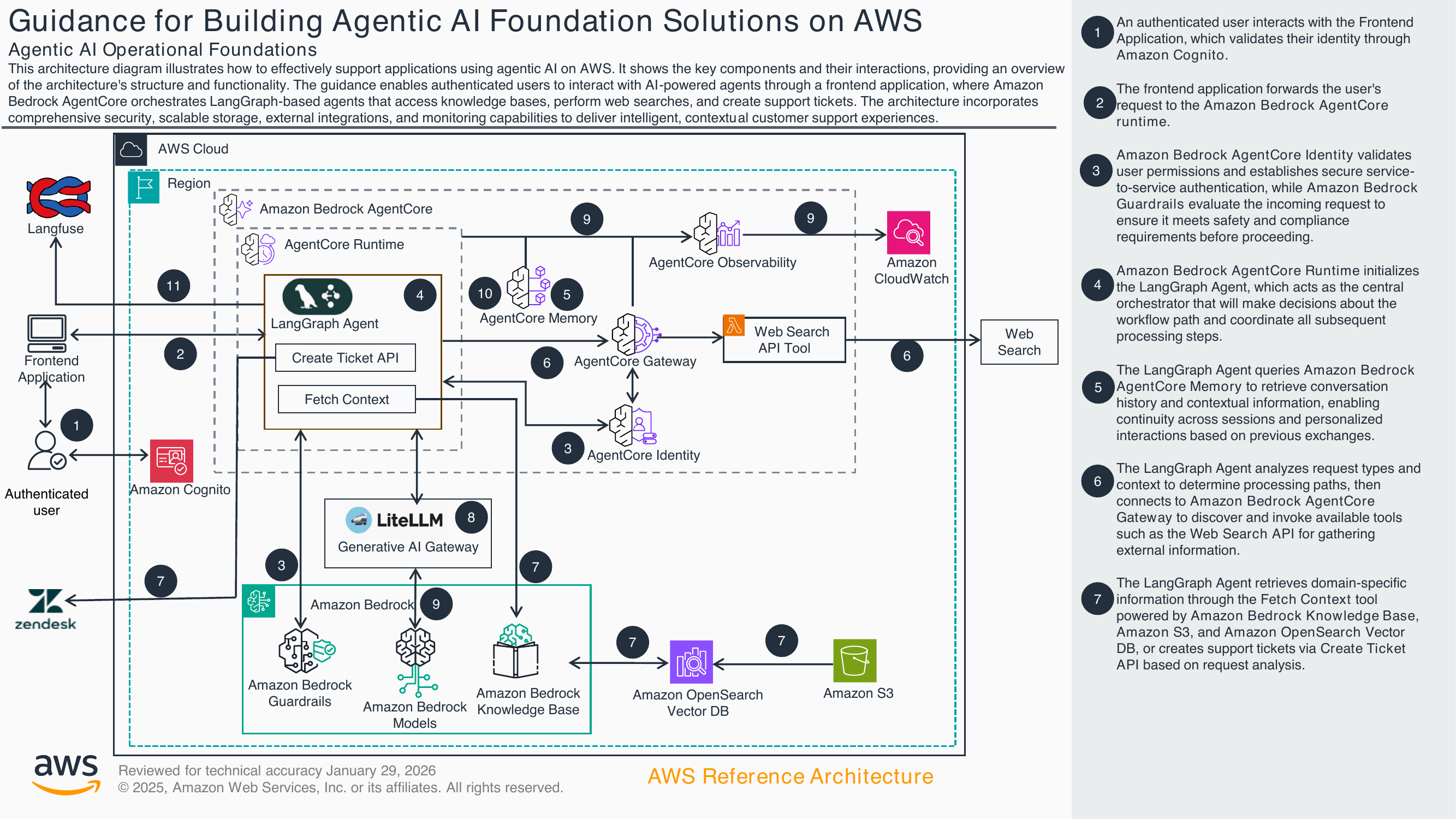
AWS published the Guidance for Building Agentic AI Foundation Solutions on AWS reference architecture (reviewed for technical accuracy on January 29, 2026). It depicts an authenticated customer-support agent built on Amazon Bedrock AgentCore — AWS's managed agent platform — orchestrating a LangGraph-shaped agent that reaches a Bedrock Knowledge Base, an external Web Search tool, and a Zendesk ticket-creation API. This artefact evaluates the architectural choices for startup fit. Pricing tiers, regional availability, and service quotas are out of scope.
What AWS actually proposes
The diagram describes an 11-step request lifecycle inside one AWS Region:
- Edge & identity (steps 1–3). A user authenticates through Amazon Cognito; the frontend hands the request to AgentCore Runtime; AgentCore Identity validates service-to-service auth and Bedrock Guardrails screens the input before any model call.
- Agent core (steps 4–6). AgentCore Runtime spawns a LangGraph agent. The agent reads conversation state from AgentCore Memory and discovers tools — including the Web Search API — through AgentCore Gateway.
- Knowledge & action (step 7). Domain context is fetched through a Bedrock Knowledge Base backed by Amazon OpenSearch Vector DB and Amazon S3. Side-effecting actions go through a Create-Ticket API to Zendesk.
- Generation (step 8). Model calls flow through LiteLLM as a multi-provider Generative AI Gateway, then to Amazon Bedrock Models with Guardrails inline.
- Observability (steps 9–11). AgentCore Observability emits to Amazon CloudWatch for system metrics, and the workflow trace is mirrored to Langfuse for agent-level inspection. AgentCore Memory is updated with the new state before the response is returned to the authenticated user.
The carousel below renders the AWS-published architecture diagram in two views — one for steps 1–7 (request → retrieval → action) and one for steps 8–11 (generation → observability → response).
Carousel
Findings
1. AgentCore is the architectural commitment, not Bedrock. The diagram puts five AgentCore primitives — Runtime, Identity, Memory, Gateway, Observability — at the centre of the request path. Each one removes a chunk of scaffolding (session state, service-to-service auth, tool discovery, trace export). Adopting the architecture means adopting AgentCore as the platform; substituting any single primitive later is a non-trivial migration. The Bedrock model choice is, by contrast, replaceable through LiteLLM.
Condition: this is a fair trade for teams already on AWS. For teams on GCP or Azure, the conceptual shape transfers but the component-by-component cost is meaningful.
2. LiteLLM is the most defensive choice in the diagram. Putting a multi-provider gateway between the agent and Bedrock Models preserves the option to route to Anthropic, OpenAI, or self-hosted endpoints without rewriting the agent. On a stack this AWS-native, that single indirection is what keeps the architecture from being a one-way door at the model layer.
3. Telemetry is split for the right reason. CloudWatch handles infra metrics (latency, error rates, throughput); Langfuse handles agent-level traces (decision paths, tool selection, prompt and completion inspection). Treating these as different jobs — rather than forcing one tool to do both — matches what production agent teams actually need. The omission, again, is cost as a first-class signal on either path.
4. Guardrails are inline, not bolted on. Bedrock Guardrails sits between the agent and the model in the data path. This is the right shape: safety checks that run only when "someone remembers to call them" do not survive contact with a fast-moving product team. The trade-off is a per-call Guardrails latency and cost that the diagram does not name.
5. The agent topology is single-LangGraph. One planner, sequential tool calls, one knowledge-base retrieval path. This works for customer-support agents and most early production deployments. It is not the right starting point for planner-executor or DAG-orchestrated multi-agent systems — those require a different boundary between AgentCore Gateway and the agent runtime that the diagram does not address.
6. OpenSearch Vector DB is heavier than most startups need on day one. Amazon OpenSearch is a strong production-grade vector store, but operating it (index sizing, replicas, snapshot policy, IAM) is non-trivial. For a pre-PMF team, a managed-vector option (Pinecone, Turbopuffer, or even pgvector inside an existing RDS instance) gets the same RAG behaviour with materially less ops cost. The architecture is sized for a team that already has OpenSearch operational comfort.
7. The diagram makes one operational pattern explicit that most in-house designs leave implicit: tool discovery through a gateway. AgentCore Gateway as the tool registry — rather than tools wired directly into the agent's prompt — is a small architectural decision with large downstream consequences for adding, deprecating, and auditing tools. This is the under-appreciated detail in the diagram.
Conditions of applicability
| Context | Fit | Note |
|---|---|---|
| Customer-support agent, AWS-native, ≥5 eng | High | The architecture is sized for exactly this case. |
| RAG-heavy advisory agent, AWS-native | High | Knowledge Base + OpenSearch path transfers cleanly. |
| Pre-PMF, <5 eng, single agent in beta | Low | AgentCore + OpenSearch ops surface is too large pre-PMF. |
| Multi-agent or planner-executor architecture | Medium | AgentCore Gateway helps; topology around it needs redesign. |
| Non-AWS team (GCP, Azure, self-hosted) | Low | Conceptual shape transfers; component substitution cost is high. |
| Regulated domain (healthcare, finance, legal) | High | Cognito, Guardrails, AgentCore Identity, and CloudWatch satisfy audit primitives. |
What the architecture does not address
- Per-conversation cost or token-spend as a first-class observability signal.
- Multi-region failover or active/active deployment.
- Multi-agent or planner-executor topologies above a single LangGraph agent.
- Eval harness — how Layer 1–4 evaluation (component, trajectory, outcome, system) is wired into the diagram.
- Lighter-weight vector stores for early-stage adoption.
- Migration path off AgentCore primitives if a team needs to leave AWS.
These are scope boundaries of the published reference, not failures of it. They are the work the reader still has to do after adopting the architecture.
Author's take (Selva, April 2026)
If I were a 10-engineer AWS-native team building a customer-support agent today, I would adopt this architecture nearly as drawn — the AgentCore primitives are doing real work and the LiteLLM indirection keeps the model layer optional. I would add per-conversation cost metrics into the Langfuse trace and into CloudWatch alarms. I would defer OpenSearch Vector DB to the second iteration in favour of a managed-vector store while the retrieval shape is still being learned. I would treat the AgentCore commitment honestly — name it as a strategic AWS bet at the architecture review, not as a default.
This is one practitioner's reading. It is not a universal recommendation.
Open questions for re-evaluation
- How does AgentCore Memory's pricing and quota envelope hold up at 10× conversation volume?
- What is the realistic Guardrails latency budget per call at p95?
- Does AgentCore Gateway scale cleanly to a tool registry of 50+ tools, or does latency degrade?
- What does the migration path off AgentCore look like if Bedrock's pricing model changes?
Re-evaluation cadence: 6 months, or sooner on a major AWS revision.
MY EVALUATION
Verdict
Moderate fit. The conceptual layering — managed identity, memory, gateway, observability — removes scaffolding work that small teams would otherwise rebuild. The deep AWS commitment and operationally-heavy components (OpenSearch Vector DB, LangGraph single-agent topology) are the costs to weigh.
Rubric scores
Conditions for adoption
- Adopt fully when: AWS-aligned infra, ≥10 engineers, regulated or audit-sensitive domain, and a single-agent customer-support / RAG product shape. AgentCore pays for itself by removing scaffolding work.
- Adopt selectively when: AWS-aligned but pre-PMF — keep Cognito + Bedrock models + Knowledge Base; defer AgentCore Memory/Gateway until you have multiple agents or a real abuse surface.
- Substitute when: not on AWS, or sub-10 engineers without a regulatory mandate. The conceptual layers transfer; components do not. Use pgvector + LangGraph + a lightweight gateway instead.
- Skip when: multi-agent or planner- executor architecture — single-agent LangGraph topology here will need redesign before this reference applies.
What to keep
- Bedrock AgentCore covers identity, memory, gateway, and observability as managed primitives, removing common scaffolding work.
- LiteLLM as the model gateway preserves provider optionality even on an AWS-native stack.
- Dual telemetry path (CloudWatch + Langfuse) recognises that infra metrics and agent-trace inspection are different jobs.
- Guardrails sits in front of the model layer, not bolted on — safety is part of the data path, not an afterthought.
Where it costs more than expected
- AgentCore is a deep AWS commitment; the conceptual layers are portable but the components are not.
- Single-agent LangGraph topology — multi-agent or planner-executor patterns need redesign.
- No cost or token-spend signal in the observability layer despite per-conversation cost being the dominant startup risk.
- OpenSearch Vector DB is operationally heavy for a sub-10-engineer team; lighter stores would fit earlier stages.
- AgentCore is a deep AWS commitment — conceptual layers port, components do not. Migration cost is real.
- OpenSearch Vector DB is operationally heavy for sub-10 engineers; lighter stores (pgvector, Pinecone) fit earlier stages with a fraction of the run-cost.
- No per-conversation cost or token-spend signal in the observability layer — add this yourself or fly blind on burn-rate risk.
Conflict of interest: none.