MCP Gateway: a single control plane for agent-tool plumbing
Decision this supports
Should we put a gateway between our agents and the MCP servers they call?
BACKGROUND
Background
Drawn from
Direct observation across small AI-product teams (5–15 engineers) running multiple MCP servers in production, plus the public posture of managed/open-source MCP gateways. Authored by Selva Ganapathy on Apr 2026.
What goes wrong without a gateway
- Security logic (tool-shadowing checks, prompt-injection defences, JWT validation) gets copy-pasted and drifts between servers.
- No central control of which agent can call which tool — allowlists multiply across N codebases.
- Observability scatters across repos and log formats; debugging spans three places.
- Every server becomes a separate attack surface for tool-injection, output exfiltration, and credential leakage.
When the pain compounds
Fastest in 5–15 engineer teams shipping fast — exactly the cohort that can't afford to tax every feature ship with security boilerplate.
THE PATTERN
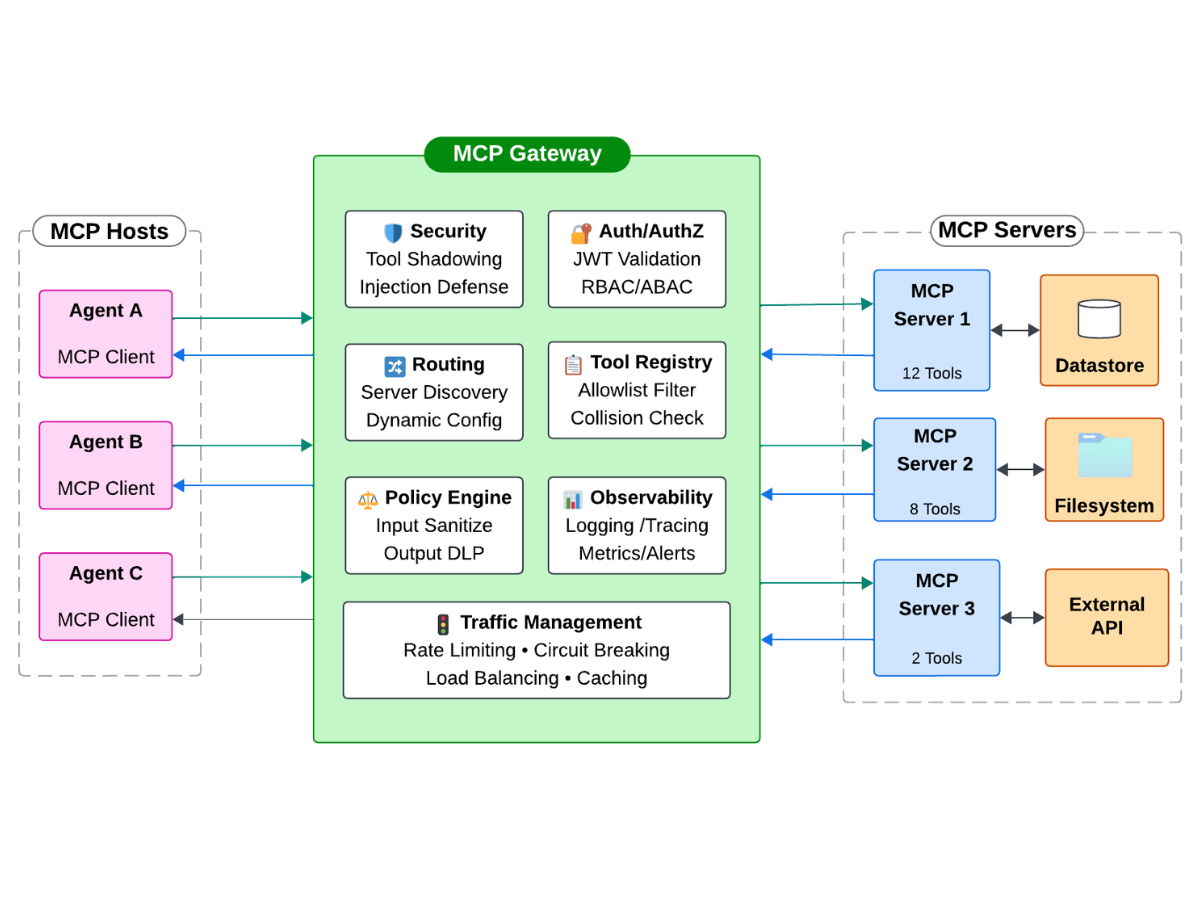
What the gateway owns
- Security — tool-shadowing prevention, prompt-injection defence, output filtering.
- Auth/AuthZ — JWT validation, RBAC/ABAC, per-agent tool filtering. New agent = one config change.
- Routing — server discovery, dynamic config, health checks.
- Tool registry — single allowlist with collision detection and schema validation.
- Policy engine — input sanitisation, output DLP, optional human-in-the-loop checkpoints.
- Observability — one dashboard, distributed tracing, audit logs.
- Traffic management — rate limits, circuit breakers, load balancing, response caching.
The MCP servers themselves get smaller and dumber — they implement tool behaviour and nothing else. That's the point.
When to use
Reach for it when all of the following hold:
- 3+ MCP servers in production (or a credible roadmap to that within a quarter).
- Multiple agents or agent personas calling those servers.
- You're shipping to real users, not internal demos.
- No dedicated security or platform team yet — the gateway is the platform.
When not to use
- Single agent, single server. Put the logic in the server.
- Throwaway prototypes.You'll throw away the gateway too.
- Team < 5 engineers with no near-term server expansion. Maintenance burden competes with shipping.
- Latency-critical tools (sub-50ms budgets). Inline policy in the server, or push to an SDK rather than a hop.
How to adopt without over-building
- Start with auth + logging only. Resist policy/DLP/breakers in v1.
- Use existing managed/open-source gateways. Far fewer teams need a bespoke gateway than think they do.
- Circuit breakers from day one — flaky downstream must not take out the fleet.
- Treat the tool registry as a release surface — version it, gate changes through review.
Full pattern write-up (with diagram and production failure modes)
The decision this pattern helps you make
If you're a startup architect or CTO running more than one or two MCP servers in production, you're about to make a quiet but expensive choice: do you keep cross-cutting concerns (auth, logging, rate limiting, policy, tracing) inside each MCP server, or do you pull them out into a single hop in front of all of them?
This artefact exists to make that choice deliberate. The TL;DR: once you hit ~3 MCP servers and any non-trivial agent fan-out, the gateway pattern pays for itself within a quarter. Below that, it's premature plumbing.
What goes wrong without it
Every MCP server I've watched a small team build started clean. Then the second one shipped, and the third, and within a sprint or two the same issues showed up across every team's retro:
- Security logic was copy-pasted. Tool shadowing checks, prompt-injection defenses, JWT validation — written three times, slightly differently, drifting in subtle ways. One server had it right; the others had stale versions.
- No central control over which agent could call what. Adding a new agent meant updating allowlists in N places.
- Observability was scattered. Debugging a misbehaving agent meant grepping logs across three repos in three formats.
- Vulnerabilities multiplied. Every server was a separate attack surface for tool-injection, output exfiltration, and credential leakage.
The pain compounds fastest in 5–15 engineer teams shipping fast — exactly the cohort that can't afford to tax every feature ship with security boilerplate.
The pattern
A single MCP Gateway sits between your AI agents (MCP clients) and your MCP servers, terminating cross-cutting concerns once.
What the gateway owns:
- Security — tool-shadowing prevention, prompt-injection defense, output filtering. Apply once, version it like a product.
- Auth/AuthZ — JWT validation, RBAC/ABAC, dynamic per-agent tool filtering. New agent? One config change, not N.
- Routing — server discovery, dynamic config, health checks. Servers come and go; clients don't notice.
- Tool registry — a single allowlist with collision detection and schema validation. Treat tools like API endpoints, not magic.
- Policy engine — input sanitization, output DLP, optional human-in-the-loop checkpoints for high-risk tools.
- Observability — one dashboard, distributed tracing, audit logs. Debug in minutes, not hours.
- Traffic management — rate limiting, circuit breakers, load balancing, response caching.
The MCP servers themselves get smaller and dumber — they implement tool behavior and nothing else. That's the point.
Why this is worth the latency
The honest cost: a gateway adds 10–50ms per call. That's real. The win is that:
- You build new MCP servers without re-implementing auth or logging.
- You update security policy in one place and it applies to every server.
- A weird production incident has a single pane of glass to investigate.
- Cost control (rate limits, per-tenant quotas, model-cost caps) lives in one place rather than being unenforceable across servers.
Net of those, the latency tax is the cheapest line item in the budget.
When the pattern earns its keep
Reach for it when all of the following are true:
- 3+ MCP servers in production (or a credible roadmap to that within a quarter).
- Multiple agents or multiple agent personas calling those servers.
- You're shipping to real users, not just internal demos.
- You don't have a dedicated security or platform team yet — the gateway is the platform.
If you're at 1 agent / 1 server / a prototype, skip it. The gateway is overhead until you have something to centralize.
When not to use it
- Single agent, single server. Just put the logic in the server.
- Throwaway prototypes. You'll throw away the gateway too.
- Team < 5 engineers with no near-term server expansion. The maintenance burden of a separate gateway will compete with shipping features.
- Latency-critical tools (sub-50ms response budgets). Inline policy inside the server may be the right call here, or push to an SDK rather than a hop.
How to adopt without over-building
A few rules I'd defend:
- Start with auth + logging. Period. Resist the urge to ship the policy engine, DLP, and circuit breakers in v1. They're dead weight until you have a server count or traffic shape that warrants them.
- Use existing solutions. There are managed and open-source MCP gateways already in the wild. Read them before you write yours. The number of teams that need a bespoke gateway is small; the number that think they do is much larger.
- Circuit breakers from day one. A flaky downstream MCP server should not take out every agent in your fleet.
- Log everything from day one. Observability is the cheapest insurance policy you'll ever buy. Adding it later is 5× more expensive.
- Treat the tool registry as a release surface. Version it, gate changes through review, don't let agents discover tools dynamically without a registered entry.
What to watch out for in production
A short list of failure modes I've seen, so you can avoid them:
- Gateway becomes the single point of failure. Mitigate with active- active deployment behind a load balancer; budget for the gateway's own SLO separately from the servers'.
- Tool registry drift. A tool gets registered for a quick experiment and never deprecated. Run a quarterly "is this still used?" sweep.
- Auth latency dominates. JWT validation can balloon if every call hits an external IDP. Cache aggressively with short TTLs.
- Cost silos move, they don't shrink. Centralizing rate limiting doesn't reduce model spend; it just makes it visible. Set budgets, not just limits.
Decision summary
If you're at the inflection point — 2 servers shipping, a third on the roadmap, agents multiplying — the gateway is the highest-leverage platform investment you can make this quarter. If you're below that threshold, don't build it. Revisit when the boilerplate starts hurting, which it will, on schedule.
Conflict of interest: none.