The 4-Layer Agent Evaluation Framework
Read original: Startup Technical Guide: AI AgentsDecision this supports
Should we adopt the 4-layer eval framework for our agent releases?
THE SOURCE
Source write-up
Purpose
An operational discipline ("AgentOps") for non-deterministic agent systems, with a four-layer evaluation split aimed at ReAct-style agents. Layer 2 is named "the most critical layer for evaluating the agent's reasoning process."
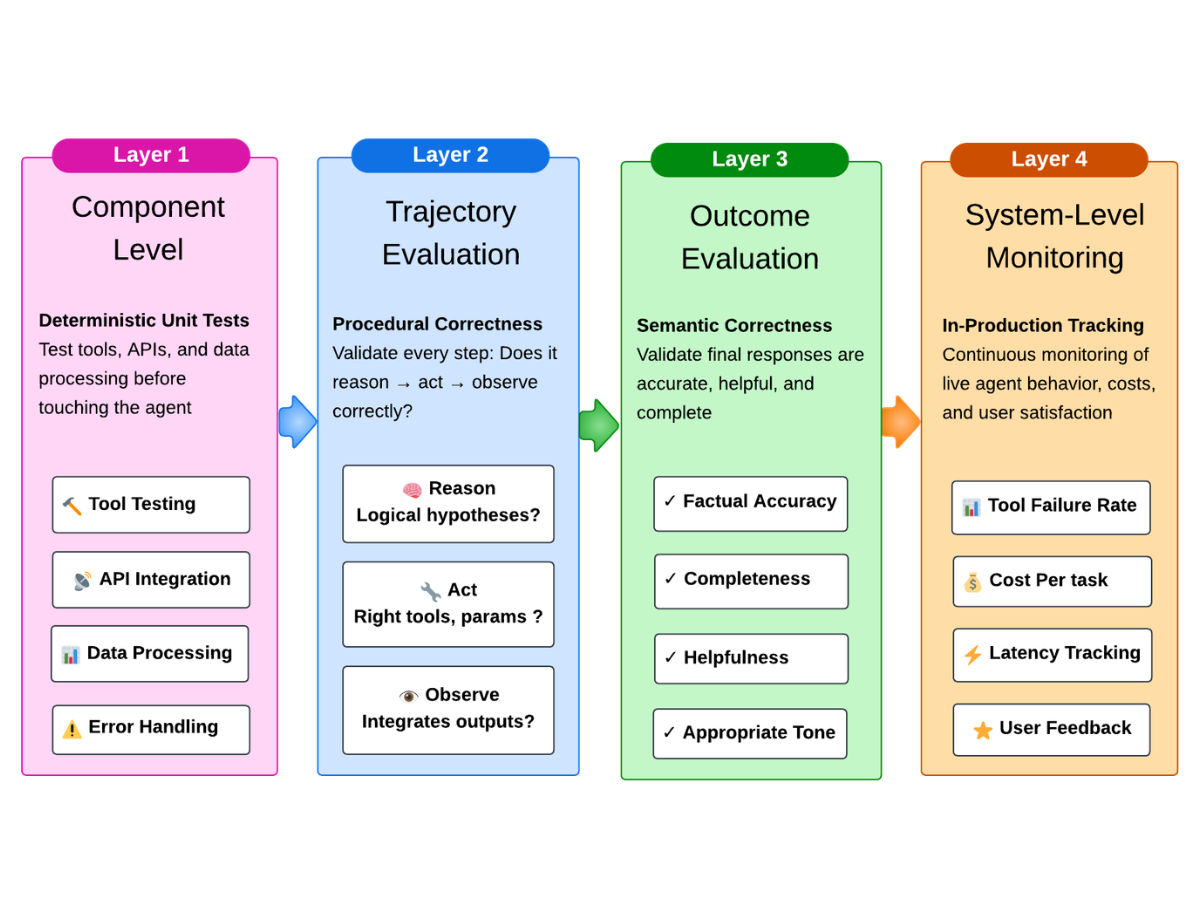
The four layers
- Component-level (deterministic unit tests) — tools, data processing, API integrations on valid, invalid, and edge inputs.
- Trajectory (procedural correctness) — programmatic checks on Reason → Act → Observe, including tool selection and parameter generation.
- Outcome (semantic correctness) — factual accuracy and grounding, helpfulness, tone, completeness of the user-facing answer.
- System-level monitoring (in production) — tool failure rates, user feedback, trajectory metrics, end-to-end latency.
Author's framing
Google frames the four-layer split as "the tangible implementation of a robust AgentOps strategy" (p. 51). Implementation guidance is anchored to ADK, Vertex AI Agent Engine, Cloud Trace, BigQuery, and Looker Studio.
Show full source preview
What this artefact evaluates
Google's Startup Technical Guide: AI Agents (April 2026) proposes AgentOps as an operational discipline for non-deterministic agent systems, and within it, a four-layer evaluation framework. This artefact evaluates the conceptual layering as a durable contribution. Google's implementation recommendations (ADK, Vertex AI Agent Engine, Cloud Trace, BigQuery, Looker Studio) are tooling choices outside the scope of this evaluation.
What Google actually proposes
In Section 3.1 (pp. 50–53), Google specifies four evaluation layers targeted at ReAct-style agents:
- Layer 1 — Component-level evaluation (deterministic unit tests): tools, data processing, and API integrations tested with valid, invalid, and edge-case inputs.
- Layer 2 — Trajectory evaluation (procedural correctness): programmatic checks on the Reason → Act → Observe loop, including tool selection and parameter generation.
- Layer 3 — Outcome evaluation (semantic correctness): factual accuracy and grounding, helpfulness and tone, completeness of the final user-facing answer.
- Layer 4 — System-level monitoring (in-production): tool failure rates, user feedback scores, trajectory metrics (e.g., ReAct cycles per task), and end-to-end latency.
Google labels Layer 2 as "the most critical layer for evaluating the agent's reasoning process" (p. 51) and frames the four-layer split as "the tangible implementation of a robust AgentOps strategy" (p. 51).
MY EVALUATION
Verdict
Context-dependent. The conceptual layering — particularly making trajectory a first-class evaluation surface — is a durable contribution. The framework is well-specified at Layers 1 and 4, under- specified at Layers 2 and 3, and silent on per-conversation cost.
Rubric scores
Conditions for adoption
- Adopt fully when: ReAct-shaped agent, ground-truth domain, ≥5 engineers, GCP-aligned infra, or regulated domain (audit trail makes Layer 4 non-optional).
- Adopt selectively when:pre-PMF, <5 engineers, single agent in beta — Layers 1 + cost-aware 4 are likely sufficient until first paying user.
- Re-define before adopting when:multi- agent or planner-executor architecture — "trajectory" needs redefinition before Layer 2 is meaningful.
- Skip when: open-ended advisory or creative agents with no ground truth — Layer 3 collapses to rubric grading without a numerator.
Where it holds at startup scale
- Layer 2 names a real practice gap. Programmatically grading the path through Reason → Act → Observe adds structure missing in mainstream ML observability.
- Layers 1 and 4 reduce to existing engineering practice — cheap to adopt, high coverage on regression risk.
- The split survives the cloud — substitute components and the conceptual layers transfer to AWS/Azure/self-hosted.
Where it under-specifies
- Layer 2 hard problem (what counts as a correct Reason step) is named, not solved. Rubric authoring and reviewer calibration are left to the adopting team.
- Layer 3 presumes ground truth. Open-ended advisory or creative agents collapse Layer 3 to rubric grading without a numerator.
- Cost is absent from Layer 4. For startup contexts, per- conversation token spend should be a co-equal signal.
- No staging by team size or product maturity — pre-PMF two-engineer teams adopting all four layers will spend most of their eng-weeks on eval infrastructure.
Full findings (6) and conditions-of-applicability table
Findings
1. The layering is novel where it counts. The framework's distinguishing contribution is making trajectory a first-class evaluation surface alongside outcome. Standard software practice already covers Layers 1 and 4. Pre-2024 ML observability covered Layer 4 plus crude Layer 3. Layer 2 — programmatically grading the path through Reason-Act-Observe — is where this framework adds structure not already present in mainstream practice.
Condition: this finding holds for ReAct-shaped agents with a single planner and sequential tool calls. For DAG-orchestrated multi-agent systems or planner-executor architectures, "trajectory" needs redefinition and the layer's leverage degrades.
2. The framework is well-specified at Layers 1 and 4, under-specified at Layers 2 and 3. Layers 1 and 4 reduce to known engineering practices. Layer 2's hard problem — what counts as a correct Reason step — is named but not solved. Google points to LLM-as-judge scoring and a "golden set" of expected ReAct trajectories (p. 51), but rubric authoring, reviewer calibration, and disagreement-resolution are left to the adopting team. Layer 3 inherits the same problem for "helpfulness" and "tone."
Implication: teams without a designated rubric author and a process for reviewer agreement will execute Layers 2 and 3 inconsistently. The framework is not self-installing.
3. Cost is absent from the framework. Layer 4 (p. 51) enumerates tool failure rates, user feedback, trajectory metrics, and latency. It does not enumerate per-conversation cost or token spend. For startup contexts, where one bad prompt can shift burn rate materially, that is a notable omission. The framework is reliability-focused; cost as a first-class signal is the reader's responsibility to add.
4. Implementation guidance is deeply tied to Google Cloud. The conceptual layers are portable — any unit-test framework, any tracing stack, any LLM-as-judge service can occupy the four positions. Google's specified implementation assumes ADK + Vertex AI + Cloud Trace + BigQuery + Looker Studio. Teams on AWS, Azure, or self-hosted infra can adopt the idea but must substitute every component. The marginal adoption cost depends heavily on existing cloud commitments.
5. Layer 3 presumes ground truth exists. "Factual accuracy and grounding" (p. 51) presumes evaluation datasets with known-correct answers. For agents in advisory, creative, or open-ended-conversation domains, ground truth is not constructible at scale; Layer 3 collapses to rubric grading without a numerator. The framework does not address this case.
6. The framework presumes a non-trivial team. Authoring trajectory rubrics, building golden-set fixtures, and maintaining reviewer calibration are research-function tasks. Layer 3 requires domain experts available to grade outcomes. A two-engineer pre-PMF team adopting all four layers will spend most of its eng-weeks on evaluation infrastructure rather than product. Google does not stage adoption by team size or product maturity.
Conditions of applicability
| Context | Fit | Note |
|---|---|---|
| ReAct agent, ground-truth domain, ≥5 eng, GCP | High | The framework is built for this case. |
| ReAct agent, ground-truth domain, non-GCP | Medium | Conceptual layers transfer; substitute components. |
| Pre-PMF, <5 eng, single agent in beta | Low–Medium | Layers 1 + cost-aware 4 likely sufficient until first paying user. |
| Open-ended advisory or creative agent | Medium | Layer 3 needs rubric-only grading; Layer 2 still applicable. |
| Multi-agent or planner-executor architecture | Medium | "Trajectory" needs redefinition; not directly covered. |
| Regulated domain (healthcare, finance, legal) | High | Audit trail and Layer 4 monitoring become non-optional. |
What the framework does not address
- Stage-banded adoption (when each layer earns its eng-weeks).
- Per-conversation cost as a first-class Layer 4 signal.
- Multi-agent and planner-executor evaluation patterns.
- Domains without ground truth.
- Comparison with adjacent practices (LangSmith eval workflows, Braintrust, Phoenix tracing, LLM observability stacks like Honeycomb or Helicone).
- Decay and re-grading cadence as underlying models change.
These are scope boundaries, not failures of the guide. They are the work the reader still has to do after adopting the framework.
Author's take (Selva, April 2026)
If I were structuring evaluation for a 5–15 engineer team shipping a ReAct agent today, I would treat Layers 1 and 4 as inviolable, treat Layer 2 as the highest-leverage of the four, and stage Layer 3 behind the availability of a domain expert to grade. I would add per-conversation cost to Layer 4 as a co-equal signal. I would treat Google's tooling recommendations as one valid implementation, not the recommended one — the right toolkit depends on cloud, language, and existing observability investments.
This is one practitioner's reading, informed by production evaluation discipline at Mintmesh. It is not a universal recommendation.
Open questions for re-evaluation
- How does Finding 1 hold up on planner-executor and DAG-orchestrated multi-agent systems?
- What is the realistic eng-week cost for a 10-person team to reach all four layers in CI/CD?
- How does Google's split compare empirically to LangSmith and Braintrust workflows on the same agent?
- Where does the framework decay first when the underlying model changes (e.g., a Gemini → Claude swap)?
Re-evaluation cadence: 6 months, or sooner on a major Google revision.
Conflict of interest: none.